
- 非エンジニアの方でPythonのデータ分析に興味がある方
- クラスタリングや次元削減の基本的な使い方を知りたい方
- 世界のヒット曲の特徴に興味がある方
はじめに
ご訪問いただきありがとうございます。本記事ではSpotifyから入手できるデータを使って、Pythonのクラスタリングや次元削減の基本的な使い方についてご紹介します。Spotifyとは、念のためご説明しますと2021年現在、3億5,600万人のユーザーを抱えている世界最大の音楽配信サービスです。そんなSpotifyでは、APIを通して登録されている曲の詳細情報(アコースティック感、ライブ感、音圧、明るさ、ダンサビリティ、テンポなど)を入手する事ができるんです。今回分析に使用するデータは、2021年7月25日時点の世界28ヶ国のTOPチャート20曲を題材にしてみました。それでは早速クラスター分析と次元削減を実施してみましょう。どのような特徴があらわれるか楽しみですね。
なお、Pythonを中高年が基礎から最速独学で学ぶ方法を別の記事でまとめていますので、よろしければご覧ください。>> 中高年の為の挫折しない最短のPython,AI・機械学習のおすすめ学習方法
>> 中高年がAI・機械学習を学ぶ為のプログラミングスクール 主要8校を徹底比較
手順
- k-meansでクラスタリング
- 国別の音楽的な特徴ランキング
- 特異値分解(SVD)で次元削減
- まとめ
ちなみに今回、選定した国は以下の28ヶ国になります。完全に著者の好みで抽出しています。皆さんもご興味がございましたら、データの入手をしてみてはいかがでしょうか。データの入手方法は別の記事にまとめていますので、ぜひ参考になさってください。

<各国の略号>
| No | 略号 | 国 |
| 1 | AR | アルゼンチン |
| 2 | AT | オーストリア |
| 3 | AU | オーストラリア |
| 4 | BE | ベルギー |
| 5 | BR | ブラジル |
| 6 | CL | チリ |
| 7 | CR | コスタリカ |
| 8 | DE | ドイツ |
| 9 | EG | エジプト |
| 10 | ES | スペイン |
| 11 | FR | フランス |
| 12 | HK | 香港 |
| 13 | IL | イスラエル |
| 14 | IN | インド |
| 15 | IT | イタリア |
| 16 | JP | 日本 |
| 17 | KR | 韓国 |
| 18 | MX | メキシコ |
| 19 | NL | オランダ |
| 20 | NO | ノルウェー |
| 21 | PT | ポルトガル |
| 22 | RU | ロシア |
| 23 | SA | サウジアラビア |
| 24 | SE | スウェーデン |
| 25 | TW | 台湾 |
| 26 | UK | イギリス |
| 27 | USA | アメリカ |
| 28 | ZA | 南アフリカ |
1.k-means法でクラスタリングを行う方法
ライブラリのインポート方法
28ヶ国5,600曲のうち、特徴をよりわかりやすくするためTOP20の曲に絞ってクラスタリングを行います。はじめに必要なライブラリをインポートします。
import pandas as pd
import scipy
pd.options.display.max_columns = None
pd.options.display.max_rows = None
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
sns.set()
sns.set(font=["Yu Gothic", "Hiragino Maru Gothic Pro"])
%matplotlib inline
import warnings
warnings.filterwarnings("ignore")データの読み込み方法
つづいてデータを読み込みます。今回使用したデータはこちらになります。ダウンロードができるようにしていますので、ぜひ一緒に手を動かして実践してみてください。
データを読み込み、さらに不要なカラムを削除しておきます。また特徴を際立たせることを目的に各国のTOP20位以上の曲を抽出してデータフレーム化しておきます。→ダウンロード
df = pd.read_csv("world_top200.csv")
df.head()
# 2021/7/25 時点のランキング
# 不要なcolumnsを削除
df1 = df.drop(["Streams","URL","type","Unnamed: 0","Unnamed: 0.1","Artist","Track Name"],axis=1)
df1.set_index('C', inplace=True) # Cをindexとしている
df1.head(2)
# Position が20位以上を抽出する
df2 = df1[(df1["Position"]) <= 20]
print(df2.shape)
df2.sample(100)df2の中身をみるとこんな感じになっています(一部)
Position | acousticness | danceability | duration_ms | energy | instrumentalness | key | liveness | loudness | mode | speechiness | tempo | time_signature | valence | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C | ||||||||||||||
| EG | 19 | 0.00112 | 0.744 | 184932 | 0.473 | 0.001360 | 5 | 0.0872 | -14.143 | 0 | 0.0533 | 128.045 | 4 | 0.375 |
| CR | 16 | 0.40700 | 0.849 | 261667 | 0.701 | 0.000000 | 6 | 0.1120 | -4.407 | 0 | 0.0600 | 98.005 | 4 | 0.505 |
| SE | 13 | 0.19900 | 0.868 | 169263 | 0.622 | 0.000086 | 3 | 0.0824 | -5.104 | 0 | 0.1900 | 95.031 | 4 | 0.625 |
| JP | 18 | 0.08790 | 0.660 | 193013 | 0.576 | 0.000000 | 3 | 0.0599 | -5.627 | 1 | 0.0363 | 80.978 | 4 | 0.561 |
| AT | 20 | 0.08100 | 0.802 | 181919 | 0.719 | 0.000000 | 4 | 0.1410 | -4.271 | 0 | 0.0792 | 101.971 | 4 | 0.336 |
クラスタリングの実装方法
クラスタリングを実施する前には、データを標準化しておきます。そうすることでデータの大小にとらわれない比較が可能になります。標準化にはStandardScalerをインポートしておきます。StandardScalerを定義付けたら、引数に先に作成したデータフレームを格納して標準化をしていきます。
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
sc_df = sc.fit_transform(df2)
sc_df = pd.DataFrame(sc_df, columns = df2.columns, index = df2.index)用意が終えたら、クラスタリングの代表的な手法であるk-means法を行っていきます。KMeansをあらかじめインポートしておきます。引数にはクラスター数を指定できます。ここではn_clustersを3にして3つのクラスターをつくってみたいと思います。モデルを定義付けて.fitで実行します。
from sklearn.cluster import KMeans
model = KMeans(n_clusters=3, random_state=0)
group_num = model.fit_predict(sc_df)3つのグループに分類できました。28ヶ国のTOP20曲、全560曲を3つのグループに分けています。このままでは、特徴をとらえきれませんのでそれぞれの変数の平均値を出して、それぞれのグループの特徴を割り出してみます。以下の表のように0,1,2のグループごとの平均値を出すことができました。
df_calc = sc_df.copy()
df_calc["グループ名"] = group_num
df_calc.groupby("グループ名").mean()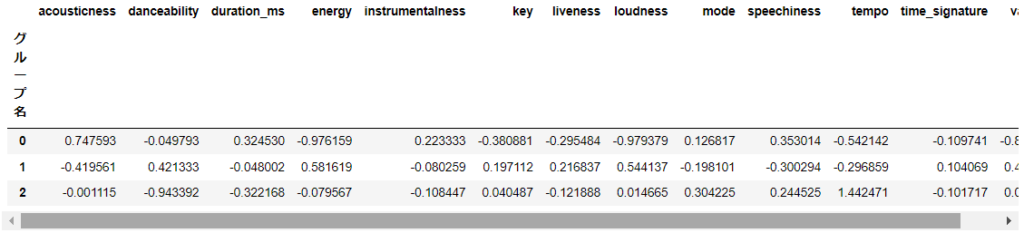
クラスタリングの可視化方法
それぞれの特徴で数値の差はありそうですが、表だけだとよくわかりませんね。グラフで可視化してみましょう。
%matplotlib inline
fig = plt.figure(figsize = (12,6))
ax = fig.add_subplot(1, 1, 1)
cluster_mean = df_calc.groupby("グループ名").mean()
cluster_mean.plot(ax=ax, kind = "bar")
#以下表示設定
plt.title("Spotify clustering", fontsize=20)
plt.xlabel("クラスター", fontsize=12)
plt.ylabel("", fontsize=12)
plt.subplots_adjust(bottom = 0.3)
plt.tick_params(labelsize=12) # x,y軸の目盛りフォントサイズ
plt.legend(bbox_to_anchor=(1.02, 1), loc='upper left', borderaxespad=0, fontsize=12)
plt.subplots_adjust(left = 0.1, right = 0.8)
# グラフにきちんとおさまるようにする
# plt.tight_layout()
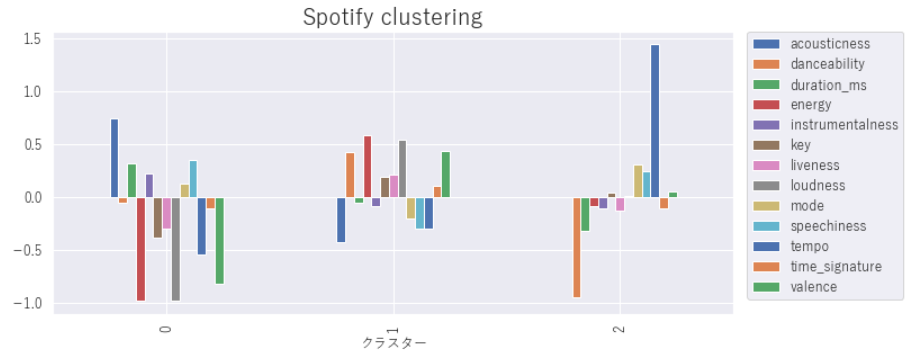
plt.show()3つのクラスターに分けてみましたが、それぞれどのような特徴をもっているでしょうか。ここでクラスタリングの注意点としては、分類されたクラスターにどのような特徴があるのかを見定めるのは、人間が実施しなければなりません。そこでグラフなどをみてそれぞれのグループにどんな特徴があるのかをよく見定める必要があります。データをじっくりみてみると、次のような特徴があるのではと考え、それぞれのグループに特徴を名付けてみました。
0:アコースティック感が強く演奏時間長めでスピーチ感強め、静かめ。
ズバリ「フォークっぽさ」
1:ダンスしやすく、エネルギッシュ、ライブ感あり、音圧高め、陽気。
ズバリ「フェスでノリノリ」
2:曲短め、スピーチ感強めでテンポが速い。
ズバリ「ラップっぽさ」
このような3パターンの特徴がありそうです。
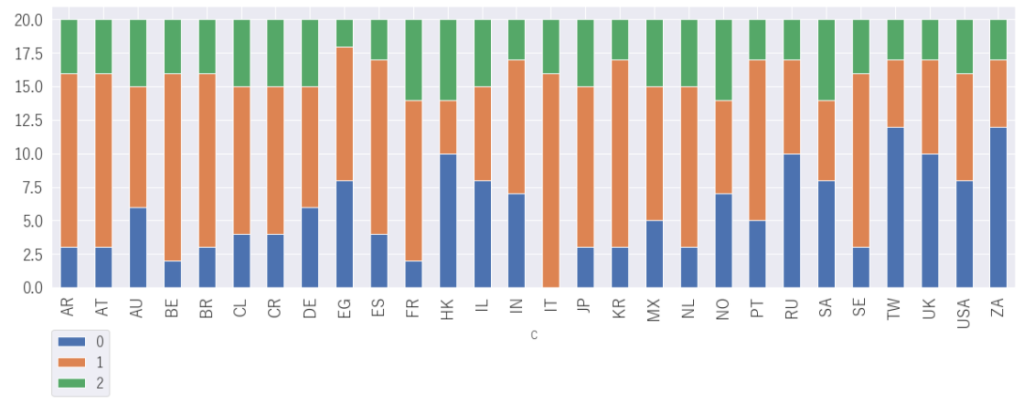
クラスタリングからみえる各国の特徴とは?
各国のクラスタリングの結果をみてみましょう
特徴的なのは0(フォークっぽい曲)がほぼゼロの国は、イタリア。さすが陽気なお国柄ですね。そして陽気な音楽である1(フェスでノリノリ)もダントツに多いですね。少し意外なのはクラシックのイメージのあるベルギーもイタリアに近い音楽性となっていますね。
逆に0が多いのは台湾、香港などのアジア勢と、意外なのは陽気なイメージ(勝手なイメージです)のある南アフリカに0が多いことですね。
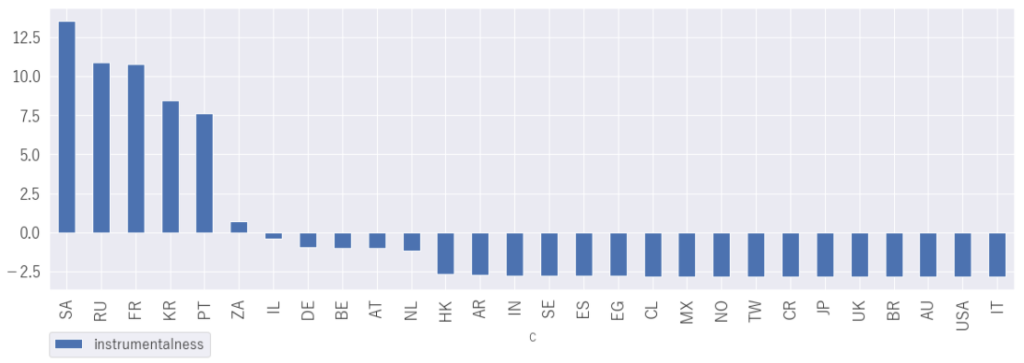
2.国別の音楽的な特徴ランキング
それぞれの特徴で国別のランキングを作成してみます。
次のようなコードで特徴別にみていきます
pv=df_calc.pivot_table( values ='instrumentalness',index = ['C'], aggfunc = sum)
pv.sort_values(by='instrumentalness',ascending=False,inplace=True)
fig = plt.figure(figsize=(20, 6))
ax = fig.add_subplot(1,1,1)
#積み上げグラフを作成
pv.plot(ax =ax ,kind='bar' , stacked=True, fontsize=18)
plt.legend(bbox_to_anchor=(0, -0.15), loc='upper left', borderaxespad=0, fontsize=16)「instrumentalness」インスト感
TOP3はサウジアラビア、ロシア、フランス
サウジアラビアやロシアは何となくインスト感強めなのは民族音楽などからも納得ですね。フランスもインスト感が強いのは意外です。フランス映画の難解さからも少し納得かな。
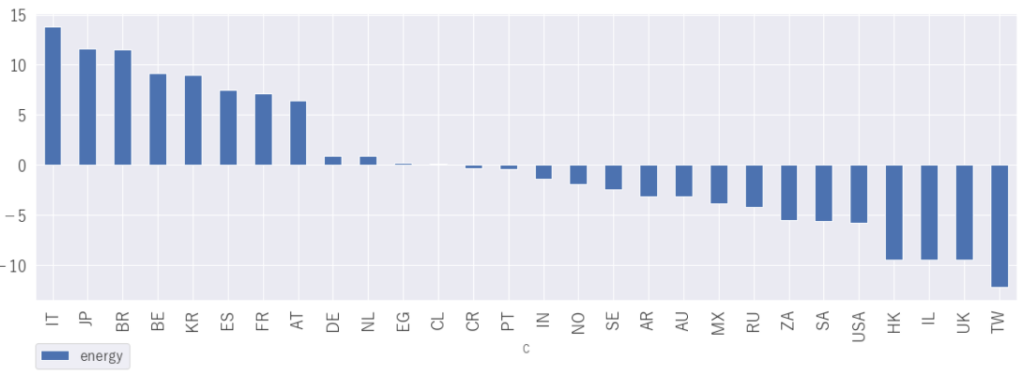
「energy」 エナジー感
TOP3はイタリア、日本、ブラジル
イタリア、ブラジルはイメージ通りですが、日本が2位とは意外です。日本の2021年7月のランキングをみるとBTSがTOP3を独占、Adoの「うっせいわ」など確かにエネルギッシュな曲が流行っていますね。
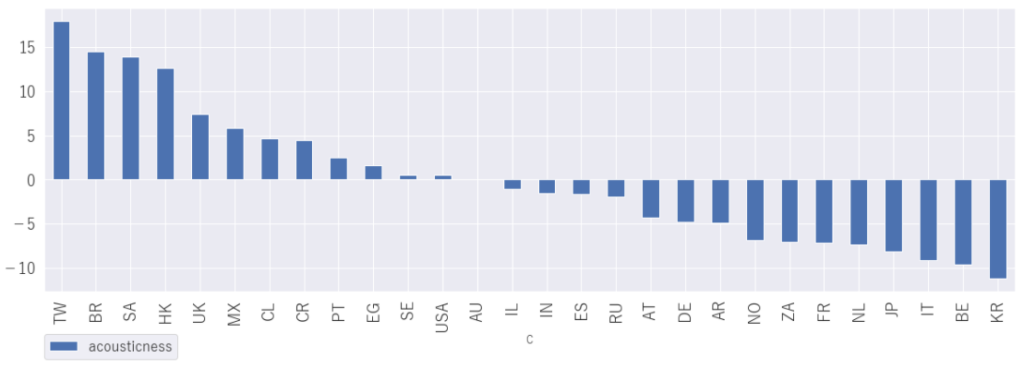
「acousticness」 アコースティック感
TOP3は、台湾、ブラジル、サウジアラビア
台湾やサウジアラビアでは民族音楽のようなイメージでアコースティック感がありそうですね。ブラジルではアコースティックなボーカルが強めの情熱的なイメージが強いと勝手に想像しています。
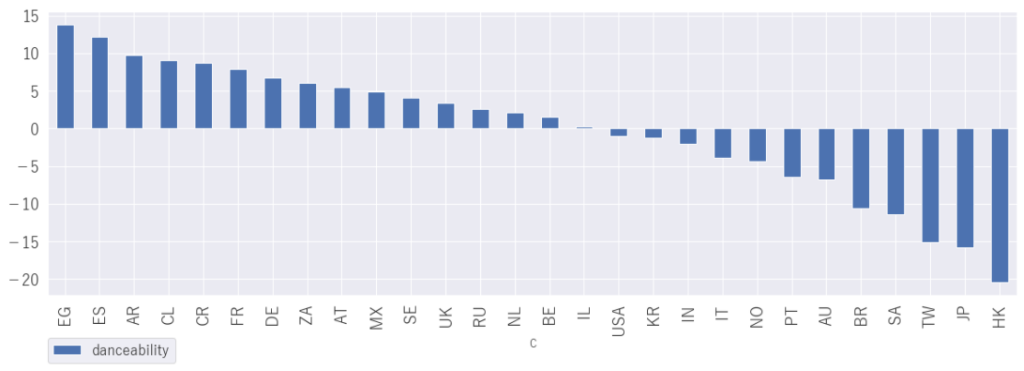
「danceability」 ダンスのしやすさ
TOP3はエジプト、スペイン、アルゼンチン
エジプトといえばベリーダンス、スペインといえばフラメンコ、アルゼンチンといえばタンゴとやはりダンスが根付いているんだなと勝手に納得。
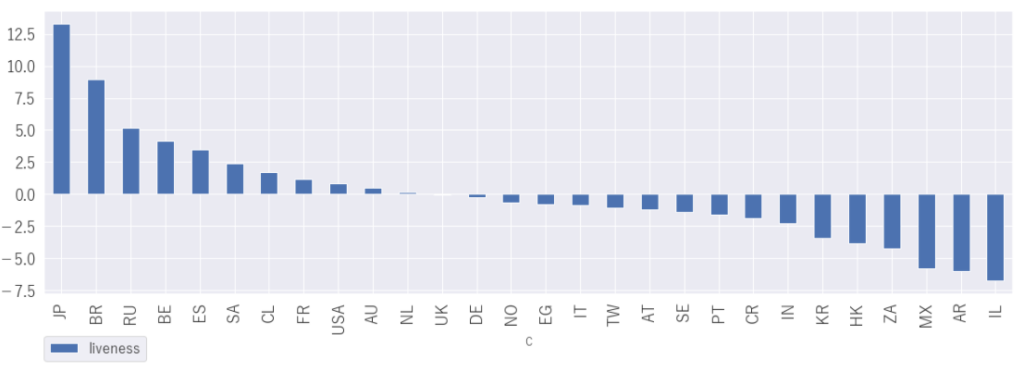
「liveness」 ライブ感
TOP3は日本、ブラジル、ロシア
日本が1位とは意外ですね。ライブ音源が多かったのかな。
「loudness」音圧
TOP3は、南アフリカ、サウジアラビア、香港
南アフリカはクラスター分析ではフォーク感強めとしながら音圧が強めと一見相反しているようにみえますが、TOP3はジャスティンビーバー、エドシーラン、リルナズXです。南アフリカの曲というよりはアメリカのチャートに影響を受けているようにもみえますね。
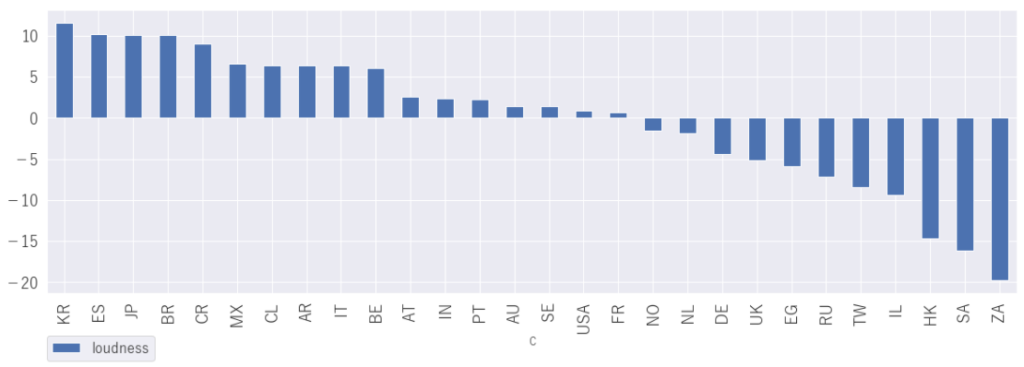
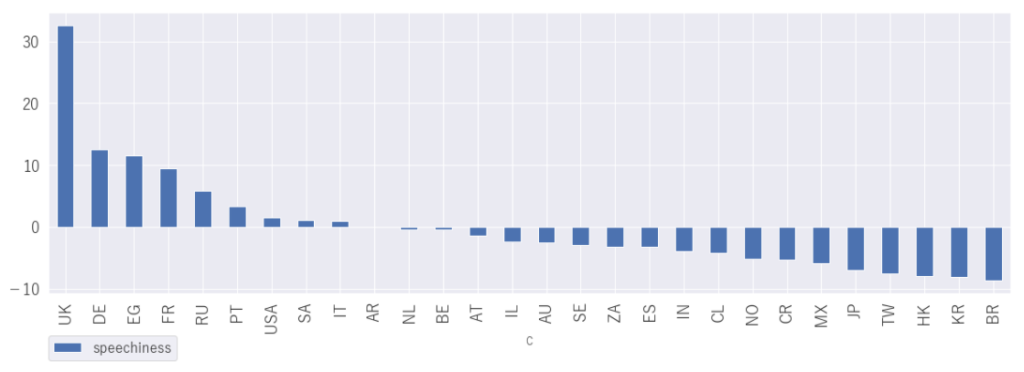
「speechiness」 スピーチ感
TOP3は、イギリス、デンマーク、エジプトですが、イギリスがダントツですね
イギリスのチャートをみるとDaveの曲がTOP20曲中7曲もランクインしています。このDaveはどんなアーティストなんでしょう。少し調べてみました。
<Dave, Stormzy>
現代UKラップの代表格であるDaveとイギリス版グラミー賞『The BRIT Awards』では「英国ソロ男性アーティスト賞」に加え「年間最優秀英国アルバム賞」も受賞しているStormzyとのコラボアルバムがイギリスの音楽チャートを席巻してますね。くわしくは下記サイトをご覧ください。個人的にはラップはあまり聞きませんが、そこまでとがった不良といった雰囲気ではなく。聞きやすい印象でした。BGMにはちょうどいいかな(ラップ好きの人からすればもっと語る事はあると思いますが)
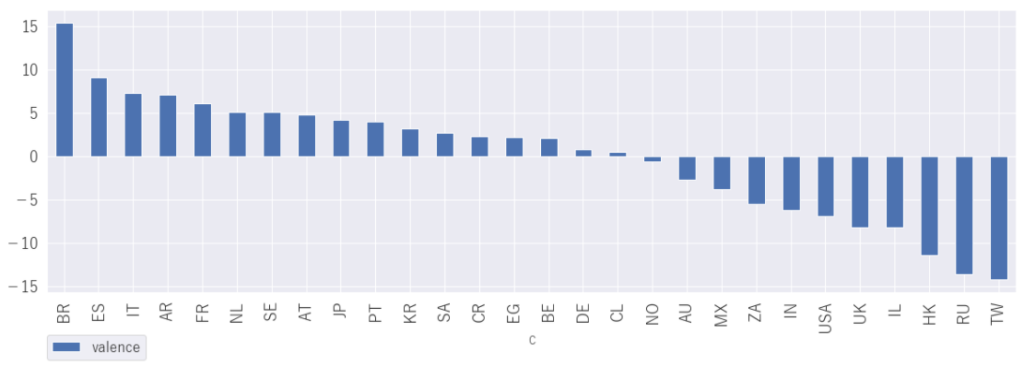
「valence」 明るさ
TOP3は、ブラジル、スペイン、イタリア
この上位3ヶ国は納得といいますか、イメージ通りですね。ちなみにブラジル、スペイン、イタリアでの2021年7月25日時点での1位の曲は次の通りです。
- ブラジル:Meu Pedaco de Pecado
- スペイン:ファルッコ
- イタリア:MI FAI IMPAZZIRE
3.特異値分解(SVD)で次元削減する方法
現時点ではアコースティック感、エナジー感、ライブ感など多くの特徴を持っていますのでそれらの特徴を可視化させるための2次元で表すのは困難です。そこで次元をギュッと圧縮して2次元のデータにすることで特徴を可視化してみます。
コードは以下のようにしました。hueを先に設定したクラスタリングのグループにすることでそれぞれのグループがどのような位置づけにあるのかがわかります。
from sklearn.decomposition import TruncatedSVD
model_svd = TruncatedSVD(n_components=2)
vecs_list = model_svd.fit_transform(df_calc)
X = vecs_list[:,0]
Y = vecs_list[:,1]
plt.figure(figsize=(8,6),frameon=False, dpi=100)
sns.scatterplot(x=X, y=Y,data=df_calc,hue='グループ名', palette='bright')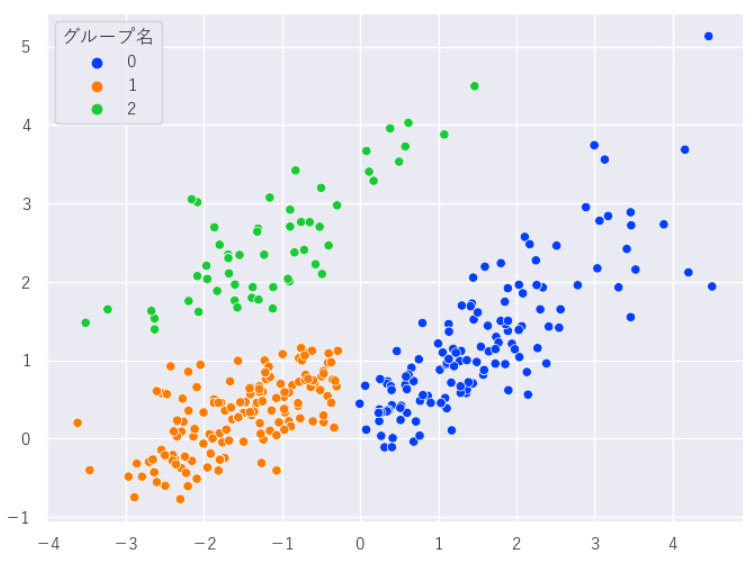
既に実施したクラスタリングのグループ分けから、x軸が大きいほど0グループ(フォークっぽさ)が強く小さいほど1(フェスでノリノリ)と2(ラップっぽさ)になります。y軸が大きいとテンポが速くラップ感が強く、小さいとダンサブルでライブ感のあるものと推察できます。
X_comp, Y_comp =model_svd.components_
plt.figure(figsize=(12,6))
sns.scatterplot(x=X_comp, y=Y_comp)
for i,(annot_x, annot_y) in enumerate(zip(X_comp,Y_comp)):
plt.annotate(df_calc.columns[i],(annot_x,annot_y))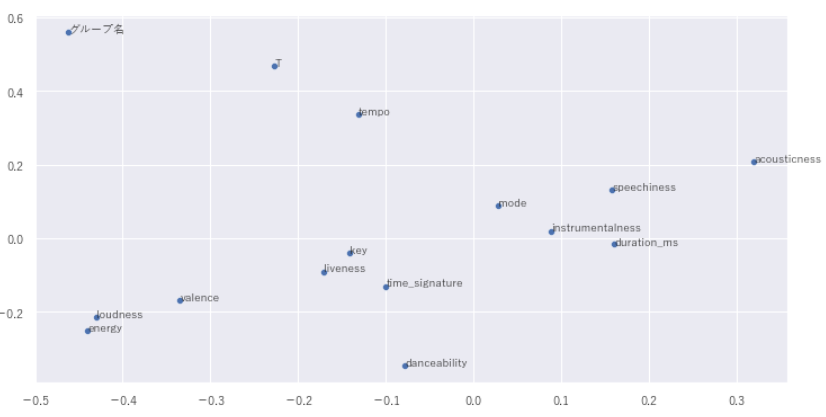
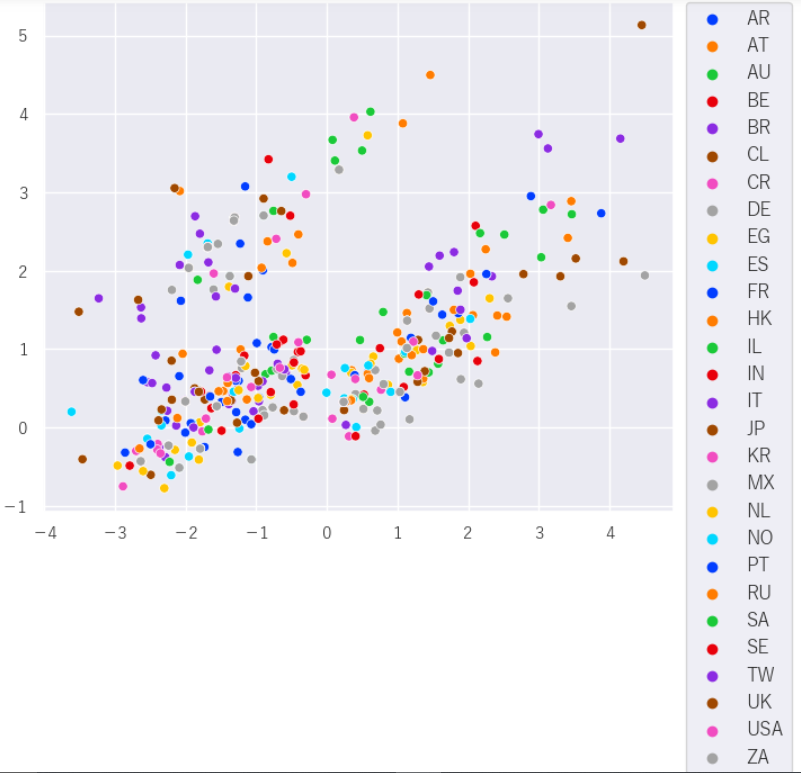
では、国別にみるとどうなっているのでしょうか
plt.figure(figsize=(8,6),frameon=False, dpi=100)
sns.scatterplot(x=X, y=Y,data=df_calc,hue='C', palette='bright')
plt.legend(bbox_to_anchor=(1.02, 1), loc='upper left', borderaxespad=0, fontsize=12)
plt.subplots_adjust(left = 0.1, right = 0.8)うーん、国別にしてもバラつきが大きくよくわかりませんね。逆に言うと各国でさまざまなジャンルの曲が流行っているということですね。
4.まとめ
最後まで読んでいただきありがとうございます。いかがだったでしょうか。クラスタリングや次元削減の基本的な使い方はご理解いただけたのではと思います。その結果無事に世界のTOPチャートも大きく3つのグループに分けられました。ただ国別にはその3つのグループの偏りはみられませんでした。世界的な音楽シーンは、ある程度大きな流れがあるという見方もできそうです。とはいえ国別に特徴別のランキングを行うと、若干国別の音楽的な好みが現れたようにも感じます。自分自身の偏見はありますが(笑)。Pythonの学習という意味では、音楽という身近な話題を元に分析することで楽しく学ぶことができたと思います。クラスタリングや次元削減は業務にも応用できる手法ですので、今回の記事が皆さんの業務の一助になれば幸いです。
SpotifyのAPIを通して、身近な音楽データを取り込めました。まだまだ面白い分析ができそうですので、また挑戦してみたいと思います。
イギリスではDaveさんというラップの大人気歌手がいることも初めての発見だったね♪(私が知らなすぎるだけという説も。。)
コメント