
エンジニア以外のごく普通のサラリーマンが普段の業務でCSVデータを扱うケースは結構少ないのではないかと思います。多くの方は日々Excelで業務をこなすことが多いのではないでしょうか。そんな環境でPythonを使う場合、読み込むデータはExcelであることが多いと思いますのでExcelでデータを読み込むケースを中心にご紹介しようと思います。
また、基礎から独学でPythonを学習する方法を別記事にまとめていますのでよろしければご覧くださいね~
必要なライブラリをインポート
まずは、必要なライブラリを読み込みます。よく「おまじない」と表現して紹介することもありますね。私の場合、余計なライブラリまで入れていますが、いちいちその度に必要なライブラリを考えて入れるのは面倒なので、ある程度使うであろうライブラリはセットものにしてコピペして入れてしまってます。これも時短ということで(笑)
ここで必須のライブラリはpandasになります。コード中ではpdと略されて使われます。
import pandas as pd
pd.options.display.max_columns = None
pd.options.display.max_rows = None
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
sns.set()
sns.set(font=["Yu Gothic", "Hiragino Maru Gothic Pro"])
%matplotlib inline
import warnings
warnings.filterwarnings("ignore")
from sklearn.model_selection import train_test_splitデータ
ここでは、ExcelファイルとCSVファイルの2種類のファイルの読み込み方について説明していきます。
Excelデータは、日本の人口のExcelファイルをダウンロードしてみましょう。ファイルを開くと2つのシートに分かれており、このうち「日本の人口(2019)」のシートをPythonで読み込む方法を紹介します。
CSVデータは、東京の気象データのCSVファイルをダウンロードしてみましょう。
ダウンロードができたら任意のフォルダに保存していただき、同じフォルダ階層でPythonを立ち上げます。ここではJupyter Notebookで実施したいと思います。
Excelデータを読み込む方法
ExcelファイルをPythonで読み込む場合には、次のようなコードで行います。
df = pd.read_excel("日本の人口.xlsx",sheet_name="日本の人口(2019)")
# または
df = pd.read_excel("日本の人口.xlsx",sheet_name=1)① pd.read_excel(“エクセルのファイル名”,sheet_name=”シートの名前”)
② pd.read_excel(“エクセルのファイル名”,sheet_name=1)
sheet_nameは①のシート名で指定するやり方と②のシートの順番で0→1→2の番号で指定することができる。
データフレームに格納する意味で、ここではdfという変数を使っていますが、ご自分の好きな名称にしていただいて構いません。
現場で使用しているExcelファイルは特にシートが分かれているケースが多い為、シートを指定してデータを読み込むことが多くよく使いますので覚えておきましょう。
head()を使ってデータを確認してみましょう。ちなみにhead()と()の中に何もない場合は初めから5行分のデータを返してくれます。()の中に初めから見たい行数を入れるとその分の行数を返してくれますよ。
例えば30行分が見たかったらdf.head(30)というように書きます。
また、tail()とするとテイル、つまり尻尾、終わりから数えた行数のデータを確認することができます。
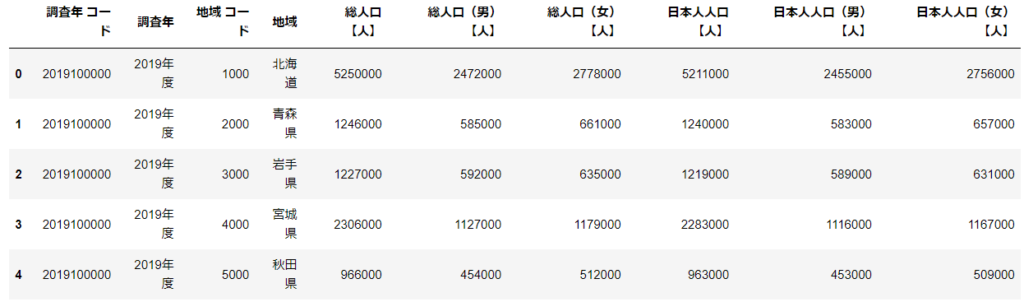
df.head()データフレームのアウトプットは次の通り。無事に読み込まれていますね。
Excelデータとして書き出す方法
続いて、読み込んだデータフレームを再度Excelとして書き出してみましょう。例えばPythonのデータフレーム上で加工した場合にそのデータフレームをExcel化して、社内資料として使用したりする場合に活用できます。
df.to_excel("日本の人口rev1.xlsx")df.to_excel(“新規Excelファイル名.xlsx”)
ファイル名は任意のファイル名を付けておきます。
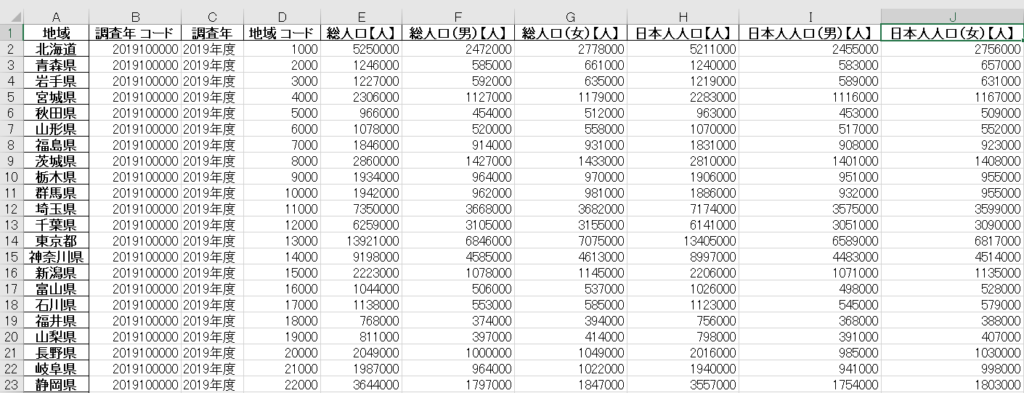
データフレームをExcel化すると下表のようになります。無事にデータフレームの情報がExcelデータとして書き出されいますね。
ちなみに完成したファイルはJupyter Notebookと同じファイルの階層に自動的に保存されますので、確認してみてください。
CSVデータを読み込む方法
続いてCSVデータを読み込む場合は次のように書きます。Excelの時とほぼ同様ですが、excel→csvにすることでCSVデータを読み込むことがで出来ます。head()でデータをみてみますが・・
df_weather = pd.read_csv("気象データ.csv")
df_weather.head()文字化けの対処方法

めっちゃ文字化けしていますね。Python3ではデフォルトでUTF8の文字コードを使っている為、shift jisの文字コードは文字化けしてしまいます。そんなときには読み込むときに encoding=”shift jis”を付けてやると文字化けは解消します。
df_weather = pd.read_csv("気象データ.csv",encoding="shift JIS")
df_weather.head()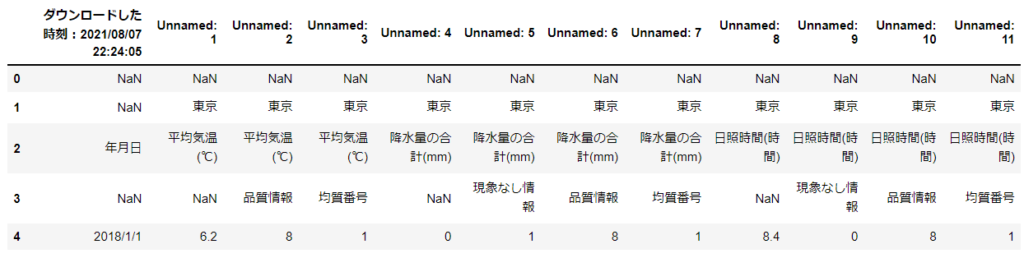
無事に文字化けは解消していますね。
CSVデータとして書き出す方法
さらにCSVデータとして書き出すこともExcel同様、可能です。
df_weather.to_csv("気象データ2.csv")ファイル名は任意のファイル名を付けておきます。
ちなみにCSVもExcel同様、完成したファイルはJupyter Notebookと同じファイルの階層に自動的に保存されますので、確認してみてください。
コメント