
- データ分析を効率的におこないたい方
- データ分析から多くの示唆を得たい方
- Pythonの初学者、非エンジニアの方
ご訪問いただきありがとうございます。本記事ではデータ分析の最も重要なステップであるEDA(Explanatory Data Analysis:探索的データ分析)を効率的に行うことができるPython のライブラリ 「プロファイルメソッド」の簡単な使い方をご紹介いたします。実際にPythonの回帰問題のチュートリアルとしても有名なボストンの住宅価格予測データを使って実際にプロファイルメソッドの使い方を解説していきます。データ分析の初学者や非エンジニアさんでもすぐに活用できるようになれれば幸いです。それではみていきましょう。
なお、Pythonを中高年が基礎から最速独学で学ぶ方法を別の記事でまとめていますので、よろしければご覧ください。>> 中高年の為の挫折しない最短のPython,AI・機械学習のおすすめ学習方法
>> 中高年がAI・機械学習を学ぶ為のプログラミングスクール 主要8校を徹底比較
「プロファイル メソッド」とは?
データ分析を行う上で最も重要な工程の一つに、データを俯瞰(ふかん)して、どこにどのような問題、課題、特徴があるかを見極める、工程「EDA」があります。普段であればデータの特徴を確認するため、主にPandasやMatplotlibを使いそれぞれのコードを入力しグラフなどにし可視化、それらを眺め示唆を得るのが一般的ですが、このメソッドを使うことで少ないコードで、基本的な情報を可視化してくれます。データ分析を効率化できるアイテムとして積極的に活用していくことができます。具体的には以下の項目を自動で出力してくれます。
本当にそんなことできるの?
まー、みてな
- Overview(データの概略)
データ全体の観測数、平均、最小、最大や欠損値、データ容量、データ種類などが確認できます。 - Variables(変数)
各変数の四分位データ、記述統計量、各種グラフが確認できます。 - Interactions(交互作用)
変数間の散布図を可視化してくれます。x軸、y軸に任意の変数を組み合わせることができます。 - Correlations(相関関係)
変数間の相関関係をヒートマップ形式にして可視化します。直感的に相関関係の強さを確認できます。 - Missing values(欠損値)
欠損値の数を可視化し、データ全体における欠損値を把握できます。 - Sample
データの最初の10行、最後の10行を表示します。データの構造を確認できます。
それでは、実際のコードとアウトプットについてみていきましょう。Jupyter notebookを使って、データ分析界では有名なボストンの住宅価格データを参考に記述してみます。
1.pandasをインポート
何はともあれ、Pandasをインポートしていきましょう。
import pandas as pd2.データの読み込み
きちんと読み込まれたことをhead()メソッドを使って確認します。
無事に読み込まれています。
df = pd.read_csv("Boston.csv")
df.head(2)
読み込まれた変数は次の通りです。
各変数の解説
- CRIME : 事件発生件率
- ZN : 単位面積当たりの住居区の占める割合
- INDUS : 小売業以外の商業が占める割合
- CHAS : チャールズ川付近か否か
- NOX : 窒素酸化物の濃度
- RM : 住居の平均部屋数
- AGE : 1940年より前に建てられた物件の割合
- DIS : ボストン市内の5つの雇用施設からの距離
- RAD : 環状高速道路へのアクセスのしやすさ
- TAX : 10,000ドルあたりの不動産税率の総計
- PTRATIO : 町ごとの教員一人当たりの児童数
- B : 町ごとの黒人の人口比率
- LSTAT : 人口における低所得者の割合
- PRICE : その地域の住宅平均価格
参考として今回の分析で使用したcsvファイルを添付しておきます。ご興味がございましたら実際に手を動かして分析をしてみてはいかがでしょうか。
Boston-2 ダウンロード
3.レポートの出力
プロファイルメソッドをインポートしてレポートとして出力させます。
pandas_profiling をインポートし、profileReportの引数に分析したいデータを格納させて実行します。たったこれだけで基本的なデータ分析が可能になります。
import pandas_profiling as pdp
from pandas_profiling import ProfileReport
profile = pdp.ProfileReport(df)
profile4.プロファイルが開始されます。
上記のコードを実行すると、下図のようなプログレスバーが表示され計算が開始されます。データ量にもよりますが、今回のような100行程度のデータなら一瞬で終了します。

データ分析の出力結果
上記の計算が終了すると、自動的に下記のようなテーブルやグラフを生成してくれます。ひとつひとつみていきましょう。
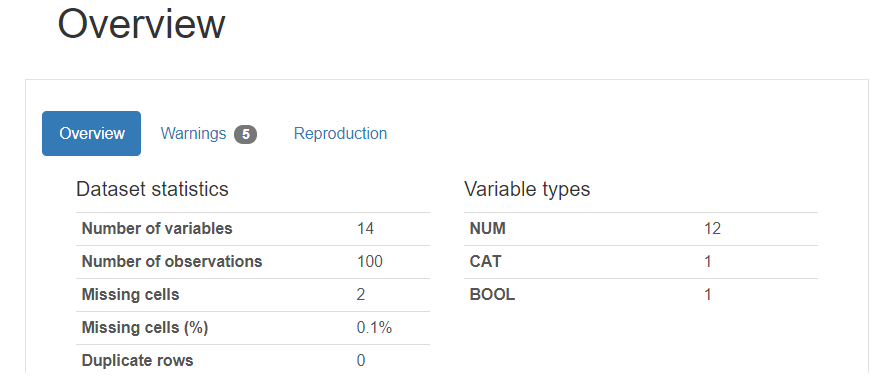
Overview(データの概略)
データ全体の観測数、平均、最小、最大や欠損値、データ容量、データ種類などが確認できます。おおまかなデータの構造を確認し、読み込んだデータに間違いがないかを確認していきます。
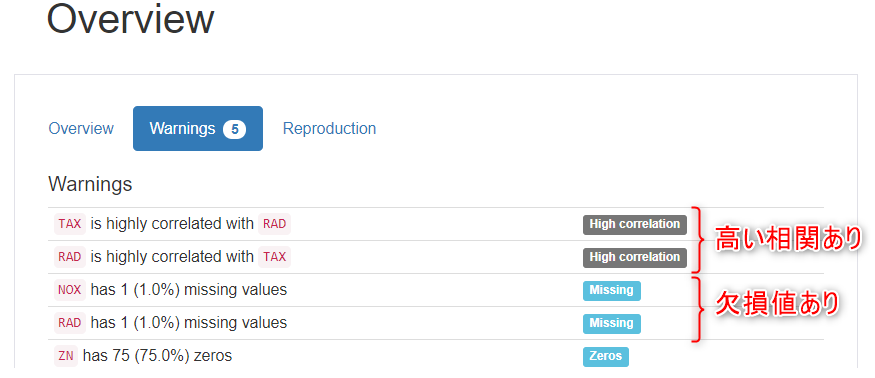
Warnings のタブでは、注目すべき特徴を教えてくれます。それぞれの変数同士の相関をみてそれぞれで高い相関があるところを「High correlation」の表示で教えてくれます。また欠損値の存在も同様に教えてくれます。ここではおおよその相関関係が分かるため、分析の示唆の方向性をざっくりと考えていきます。例えばTAXとRADの相関が高いということは、税率が高いことと交通アクセスの利便性は関係がありそうだなといった見方ができるわけです。
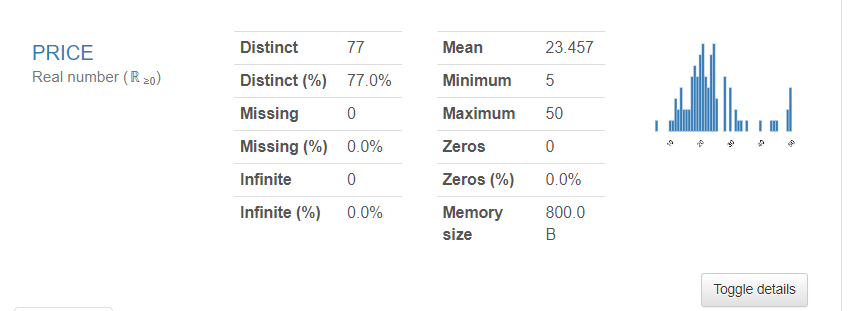
Variables(変数)
各変数の四分位データ、記述統計量、各種グラフが確認できます。
代表データとしてPRICEのデータをみていきましょう。
Distinctは同じデータの数です。ここでは同じ金額のデータが77件あるということです。Meanはご存じの通り平均値。Minimum,Maximumもあらわされています。さらに右下にある「Toggle details」をクリックすると詳細なデータが展開されます。
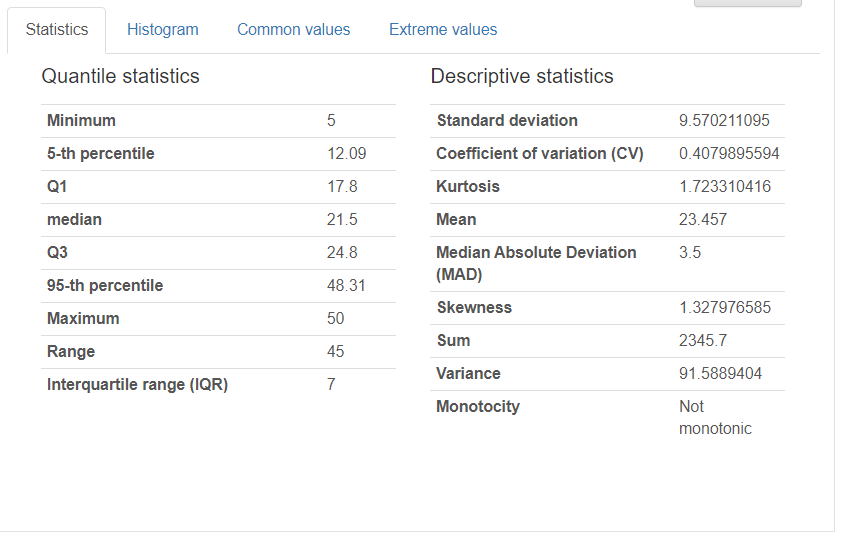
Toggle detailsで詳細を開くと下図のような画面になり、Statistic、Histogram、Common values、Extreme valuesタブがあらわれます。
最初のStatisticタブを開くと四分位範囲のデータと基本統計量を確認することができます。
Histogramタブでは、みなれたヒストグラムがあらわれます。ただしbinsの数は自動的に設定され調整することはできません。
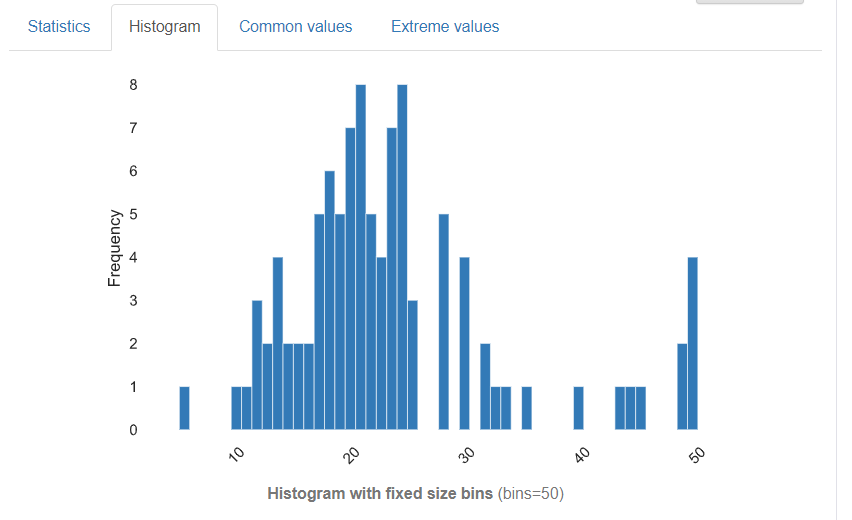
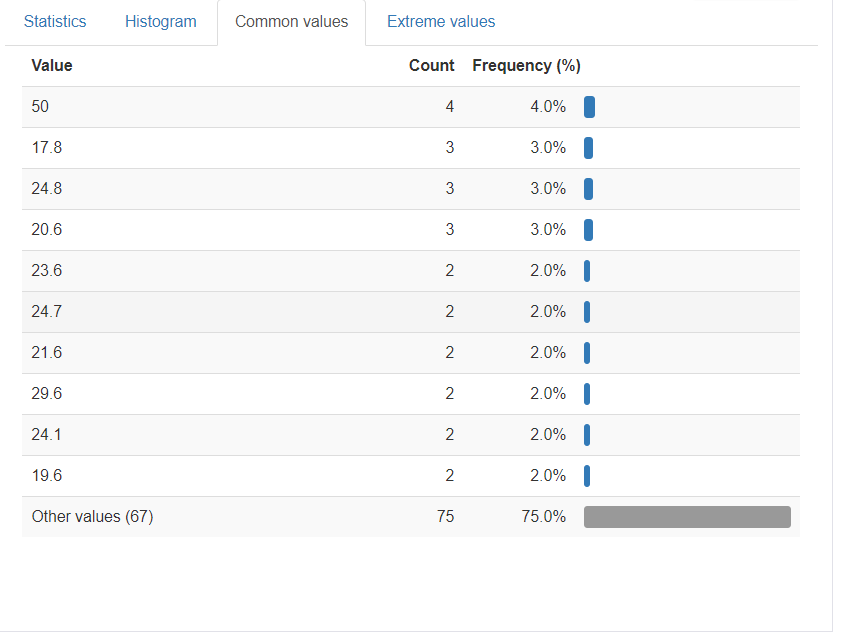
つづいて、Common valueです。
これは、同じ数値のデータがどれだけあるかをあらわしています。例えば一番上のValue 50は全部で4つあり、全体の割合の4%に相当しますよということをあらわしています。特に同じ数値がある場合それが偶然なのか、間違いなのかの確認にもつながります。
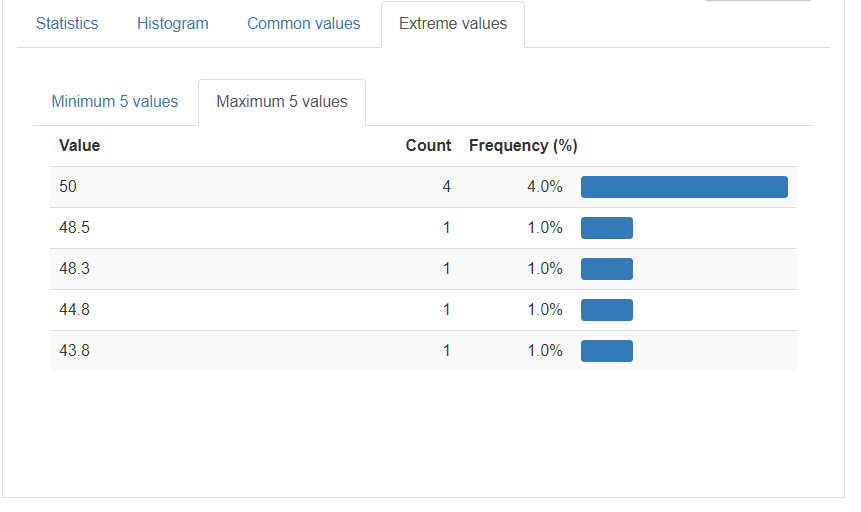
次に、Extream valuesです。
ここにはMinimum 5 ValuesとMaximum 5 Values のタブがあらわれます。これは上位、下位5つのデータをあらわします。
Interactions(交互作用)
変数間の散布図を可視化してくれます。左のそれぞれのパラメータをx軸、y軸にクリックし選択すると自動的に右側のグラフが切り替わります。x軸、y軸に任意の変数を自分自身で組み合わせることができるので仮説をたてながら検討することもできます。
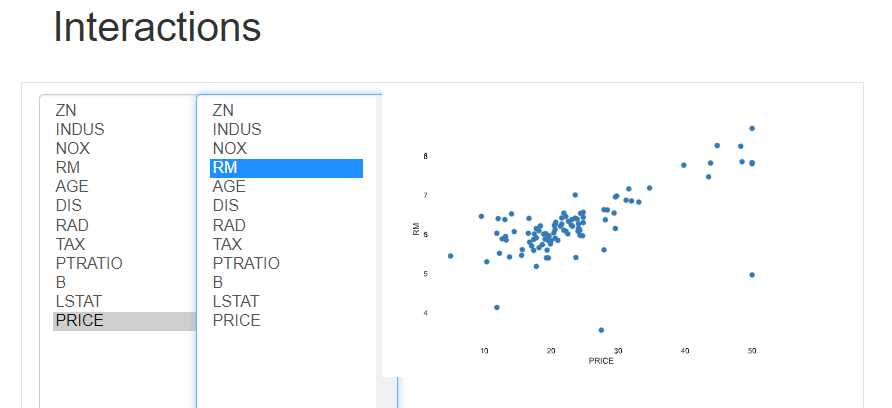
クリックでのボタン操作で組み合わせが変えられるから、直感的にデータが確認できるね。仮説を考えながらデータを眺めてみましょう。やっぱり部屋数と価格には相関がありそうだなぁ
Correlations(相関関係)
変数間の相関関係をヒートマップ形式にして可視化します。直感的に相関関係の強さを確認できます。
Pearson’sr、Spearman’s、Kendall’s、Phik といったタブがあらわれます。これは何をあらわしているかというと「相関関係の種類」をあらわしています。それぞれのタブで相関係数が変わっていきます。必要に応じて相関係数を使い分けるのもいいですね。
Pearson’sr(ピアソンの相関係数)
最も一般的に使われる相関係数です。元のデータの分布を仮定するいわゆるパラメトリックなデータ、データが正規分布に従っているときにもちいられます。
Spearman’s(スピアマンの相関係数)
元のデータの分布を仮定しないノンパラメトリックなデータで、2つの変数が同じように変化するかによって使い分けがされます。 非線形な相関をあらわすのにすぐれています。
Kendall’s(ケンドールの相関係数)
スピアマンと同様、ノンパラメトリックなデータのときにもちいられ、2つの変数の大きさの順位によって相関がきまってきます。2つの変数間の序数の関連を測定します。
Phik (φ)
カテゴリ変数、序数変数、区間変数の間で一貫して作用する新しい実用的な相関係数で、非線形依存性を取り込み、二変量正規の正規分布の場合にはピアソン相関係数に戻ります。豊富なドキュメントが利用可能です。
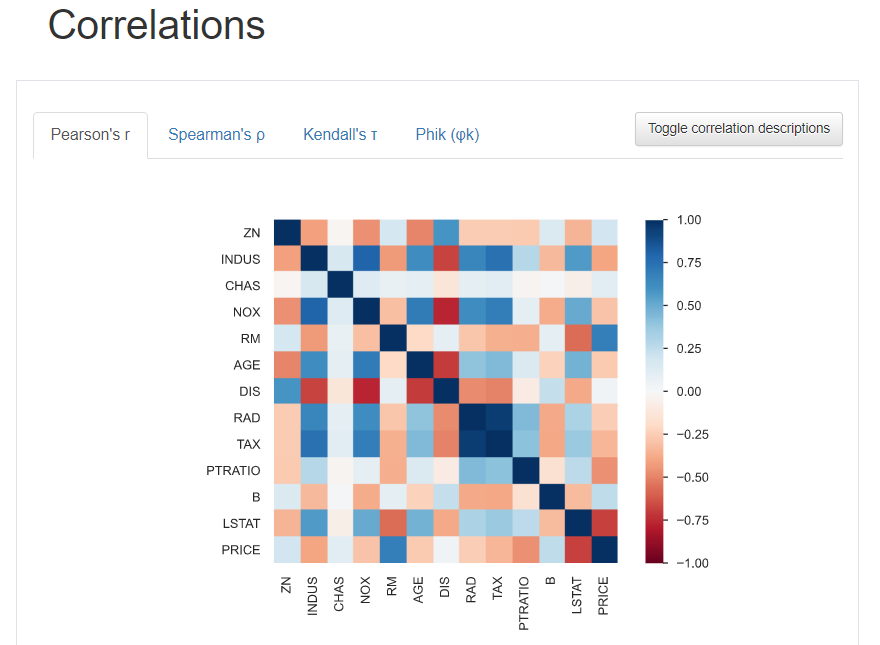
見た目もきれいだね~、直感的に相関の強弱がみえてくる~
他にもLSTAT(人口における低所得者の割合)と価格には相関がありそうだな。
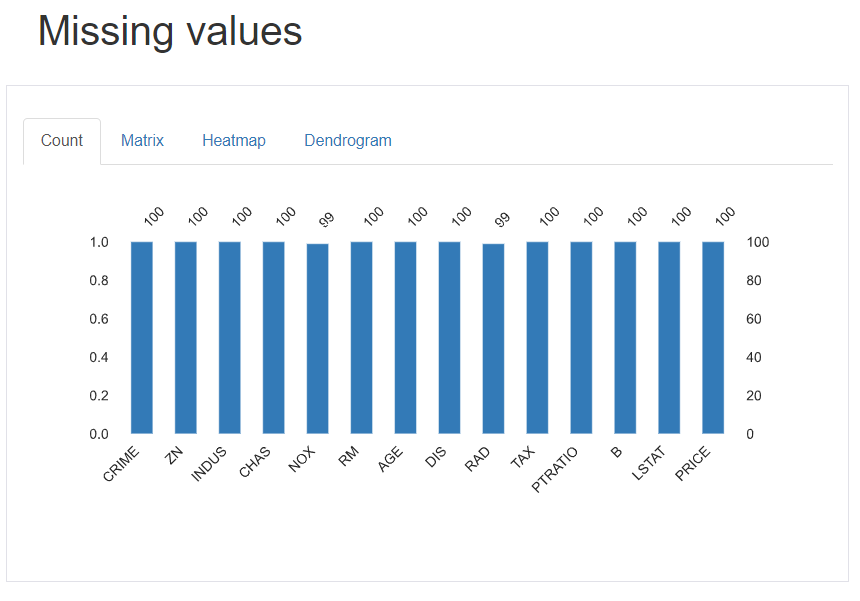
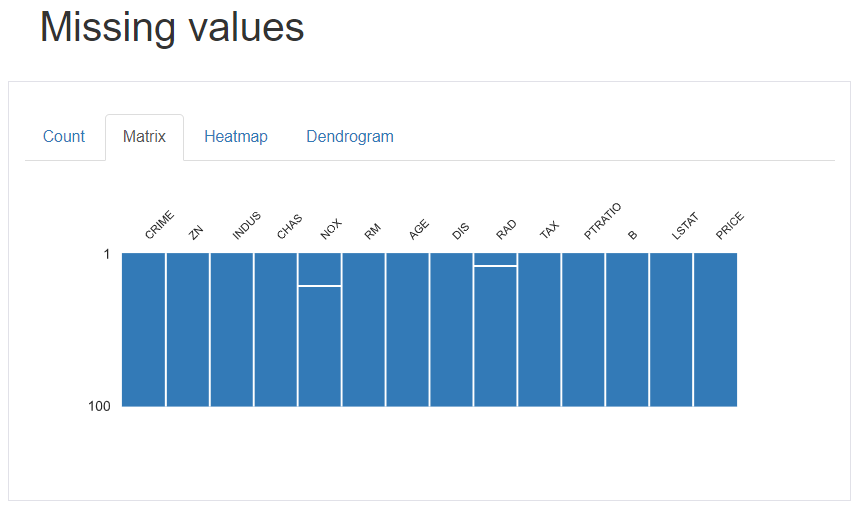
Missing values
欠損値の数を可視化し、データ全体における欠損値を把握できます。
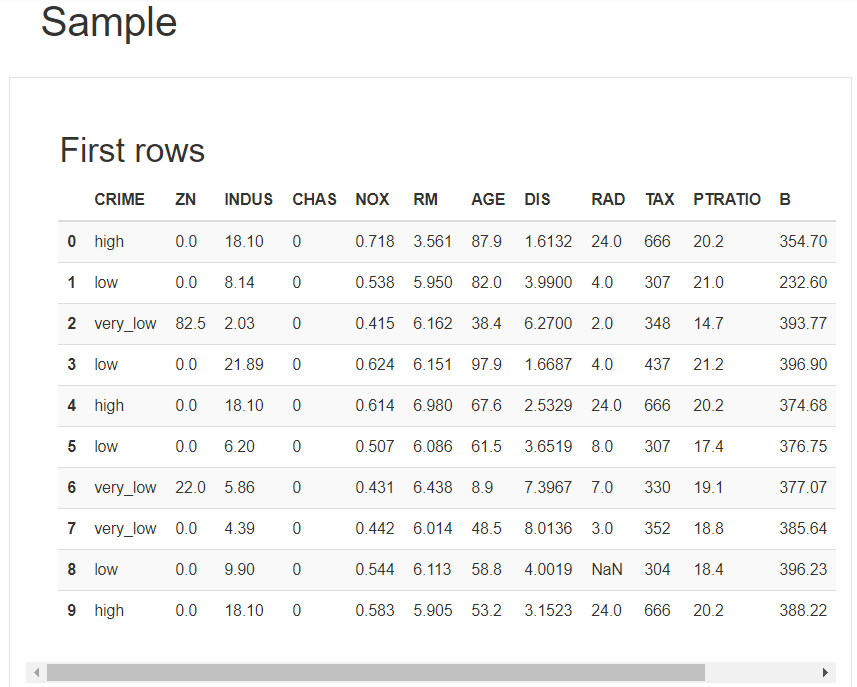
Sample
データの最初の10行、最後の10行を表示します。データの構造を確認できます
かんたーん、便利、すごーい。これだけでも色々気づきがでてくるね。
詳細解析に入る前に、データを俯瞰することがポイントだね。どんな仮説がたてられそうかな?
まとめ
最後まで読んでいただきありがとうございました。いかがだったでしょうか。わずかなコードでこれだけのデータ分析に必要な基本情報が出力されてしまいます。魔法のようですね~。効果的な使い方ができるのではないでしょうか。また、データ分析の第一歩として、詳細解析に入る前に全体データを眺めて、データが何を訴えかけているのかじっくり考えてみましょう。何より、自分が何の目的のために分析しているのかを再認識することも忘れないようにしたいですね。意外にもデータ分析に夢中になると目的を見失うことも多くあるかと思いますので気を付けましょう。今回ご紹介したプロファイルメソッドが皆さんの業務の一助になれば幸いです。効果的にデータ分析をすすめ、ビジネス課題をクリアしていきましょう!
それでは、またね~

コメント