
- 非エンジニアでPythonの機械学習を学んでいる方
- とにかく性能の高いアルゴリズムを探索したいという方
- 便利なライブラリをお探しの方
ご訪問いただきありがとうございます。こんにちは のびすです。みなさん、機械学習をしていくうえでアルゴリズムの選定どうしていますか?とりあえずランダムフォレスト、XGBoost、LightGBMなどを使うことが多いのではと思いますが、いや、待てよ、知らないだけでもっとすごい性能のアルゴリズムがあるのでは?と思うことはありませんか。わたしは思っていました。そこで今回は、そんな疑問を払拭してくれるライブラリ「all_estimators」を紹介いたします。
なお、Pythonを中高年が基礎から最速独学で学ぶ方法を別の記事でまとめていますので、よろしければご覧ください。>> 中高年の為の挫折しない最短のPython,AI・機械学習のおすすめ学習方法
>> 中高年がAI・機械学習を学ぶ為のプログラミングスクール 主要8校を徹底比較
はじめに
”all_estimators” はPython機械学習で最適なアルゴリズムを選択できる最強ライブラリです。
機械学習を進めていくと、アルゴリズムって何が最適なんだろう???って疑問がわいてきませんか?。例えば、回帰であれば、手始めにlinear regression→決定木→ランダムフォレスト→Light GBM→XGBoost 、あれ?ほかにも世の中色んなアルゴリズムがあるはず。でも全部を一つ、一つ確認するとなると気が遠くなりますね。
そうそう、なんか隣の芝は青く見えるというか、他にも知らないだけですんごいアルゴリズムがあるんじゃないの??とか思っちゃう どーしたらいいの!?
そんなとき使えるのが
all_estimators です。
分類、回帰のどちらにも対応可能。アルゴリズムを選定する際のおおよその目安として大活躍間違いなしです。それではさっそくやり方を見ていきましょう。
【分類】 アヤメの分類問題で実際に試してみよう
はじめに分類問題を使ってall_estimatorを試してみましょう。例題は分類問題では超有名なアヤメの分類問題を使ってみていきましょう。
1.まずは、必要なライブラリをインポートしていきます。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import warnings
warnings.filterwarnings("ignore")2.続いて、今回使用するアヤメのデータセットを読み込みます。
参考にデータセットも添付しておきます。データセットはこちらからダウンロードできます。ご興味がございましたらダウンロードしお試しください。
iris = pd.read_csv("iris.csv", encoding="utf-8")ざっくり、中身を確認します
iris.head(2)
3.欠損値があるので、取り合えず平均値で埋めておきます。
iris.isnull().sum()
iris=iris.fillna(iris.mean())4.次に目的変数と説明変数に分けます。
t = iris["Name"]
x = iris.drop("Name",axis=1)5.次に訓練データとテストデータに分けます。
ここまで、単純に欠損値を埋めただけですね。特徴量の分析などもありますが、ここでは割愛します。次の段階で、どんなアルゴリズムが最適か考えていきます。
どのアルゴリズムしようかな??? 迷う~。
x_train,x_test,y_train,y_test = train_test_split(x,t,test_size = 0.2,train_size = 0.8,shuffle = False)6.そこで all_estimators の出番です!
分類のアルゴリズムの正解率を出力して、比較してみよう
評価は Accuracy_score で出力してみます。
# classifierのアルゴリズムすべてを取得する
import warnings
from sklearn.utils.testing import all_estimators
from sklearn.metrics import accuracy_score
allAlgorithms = all_estimators(type_filter="classifier")
for(name, algorithm) in allAlgorithms:
try:
clf = algorithm()
clf.fit(x_train,y_train)
y_pred = clf.predict(x_test)
print(name, "accuracy score = ", accuracy_score(y_test,y_pred))
except:
print(" - ERROR:", name)
pass7.出力結果
結果からは、Perceptron accuracy score が0.966と非常に良いスコアを出しています。
今後の詳細検討では、このアルゴリズムも検討範囲に入れて進めることができますね。

【回帰】 ボストンの住宅価格で実際に試してみよう
分類につづき、回帰問題を試してみます。例題は回帰問題では有名なボストンの住宅価格の推定です。
1.まずは、必要なライブラリをインポートしていきます。
使わないライブラリも入っていますがお気になさらず。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
sns.set()
sns.set(font=["Yu Gothic", "Hiragino Maru Gothic Pro"])
%matplotlib inline
import warnings
warnings.filterwarnings("ignore")
from sklearn.model_selection import train_test_split2.続いて、今回使用するボストンの住宅価格のデータセットを読み込みます。
参考にデータセットも添付しておきます。データセットはこちらからダウンロードできます。ご興味がございましたらダウンロードしお試しください。
df = pd.read_csv("Boston.csv")中身をざっくり見てみます。
df.head(2)
3.欠損値があるので、取り合えず平均値で埋めておきます。
df = df.fillna(df.mean())
df.isnull().sum()4.次に目的変数と説明変数に分けます。
t = df["PRICE"]
x = df.drop(["PRICE","CRIME"],axis=1)5.次に訓練データとテストデータに分けます。
ここまで、単純に欠損値を埋めただけですね。分類の時と同様に all_estimators の出番です!
X_train,X_test,y_train,y_test = train_test_split(x,t,test_size = 0.7,random_state=0)6. all_estimators で学習
評価は RMSE で出力してみます。
# regressionのアルゴリズムすべてを取得する
import warnings
from sklearn.utils.testing import all_estimators
from sklearn.metrics import mean_squared_error
allAlgorithms = all_estimators(type_filter="regressor")
for(name, algorithm) in allAlgorithms:
try:
clf = algorithm()
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(name, "RMSE = ",np.sqrt(mean_squared_error(y_test, y_pred)))
except:
print(" - ERROR:", name)
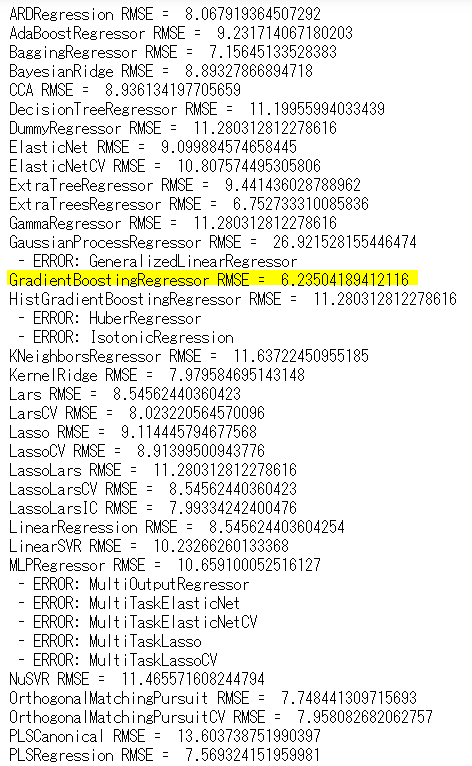
pass7.出力結果
結果からは、GradientBoostingRegressor が6.23と非常に良いスコアを出しています。
分類と同様、詳細検討では、このアルゴリズムも検討範囲に入れて進めることができますね。
まとめ
最後まで読んでいただきありがとうございました。いかがでしたでしょうか。便利ですよね。少ないコードでおおよそのアルゴリズムの狙いが定まります。忙しいビジネスマンにとっては有益なツールなので、ぜひ使ってみてください!ただし、選定されたアルゴリズムが実務にそのまま使えるかどうかは、よくよく調べて実装する必要がありますのでご注意ください。
アルゴリズムっていっぱいあるんだね~、迷っちゃうけどこのメソッドである程度絞れそうね♪ それでは、ばいばーい
![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/21ca6367.3f3c2674.21ca6368.ba24add4/?me_id=1314405&item_id=10000010&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Ff454061-tsuno%2Fcabinet%2Ftop1%2F5804-30000770-0212.jpg%3F_ex%3D128x128&s=128x128&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")
分析手法はあくまでもツールですので、うまく利用して本来の目的である
ビジネス課題の解決をしていきましょう。それではまた~
コメント