- Pythonの初学者でありながら、楽して分析したいという方
- PythonをExcelのように使いたい方
- Pythonで便利なライブラリをお探しの方
ご訪問いただきありがとうございます。今回は、ずぼらな私がおすすめする。簡単ピボットアイテムを紹介します。PythonでもExcelのピボットテーブルのように簡単に使える機能ってないのかなぁと思った人は少なくないと思います。そんなあなたに贈るPython版ピボットテーブルライブラリ「pivottablejs」をご紹介いたします。
はじめに
Pythonでデータを眺めるときにコードでpivot_tableやgroupbyを使って、データ同士の関係性を確認していると思いますが、「いちいちコードを書くのが面倒だなぁ、エクセルのピボットテーブルのように直感的に操作出来ないかなぁ?」などと感じた事はないでしょうか?
私は、いつも思っていました。
普段は断然エクセルを使うことが多いので、たまにPythonを使うと面倒に感じていました。そんな私のような面倒くさがり屋さんでも、簡単にエクセルのようなピボットテーブルがPythonで実装できるライブラリがあるのです。その名も
”pivottablejs(ピボットテーブルジェイズ)”
さっそく、実装方法を確認していきましょう。
楽しみ~♪
つかいたーい!
なお、Pythonを中高年が基礎から最速独学で学ぶ方法を別の記事でまとめていますので、よろしければご覧ください。>> 中高年の為の挫折しない最短のPython,AI・機械学習のおすすめ学習方法
>> 中高年がAI・機械学習を学ぶ為のプログラミングスクール 主要8校を徹底比較
pivottablejs の準備と基本操作方法
pivottablejs(ピボットテーブルジェイズ)のインストール
いくつかやり方はありますが、ここではanaconda prompt からインストールを行います。
conda install pivottablejsタイタニックのデータを使ってみてみよう
pandasをインポートしてデータを読み込みます。ご存じのタイタニックのデータを添付しておきますのでよろしければ使ってみてください。
import pandas as pd
df = pd.read_csv(data1)data1 ダウンロード
pivottablejs(ピボットテーブルジェイズ)を使う際の注意点!
下記のようにコードを入力すると、データのカウント数と同数のnullが発生し、正確な集計が出来ません。pivottablejsのバグなのかどうかわかりませんが、データ数に存在しないnullが出現し数値がダブルカウント状態になってしまいます。
import pivottablejs
pivottablejs.pivot_ui(df)このコードだけじゃ、うまく集計ができないよ。
pivottablejs(ピボットテーブルジェイズ)を実装する
上記のコードを入れる代わりに、以下のコードを入力することで正確に集計が可能になります。
def pivot_ui(df, **kwargs):
import pivottablejs
class _DataFrame(pd.DataFrame):
def to_csv(self, **kwargs):
return super().to_csv(**kwargs).replace("\r\n", "\n")
return pivottablejs.pivot_ui(_DataFrame(df), **kwargs)
pivot_ui(df)少し長いけど、おまじないと思って入力してみてね。
pivottablejs(ピボットテーブルジェイズ)の基本操作方法
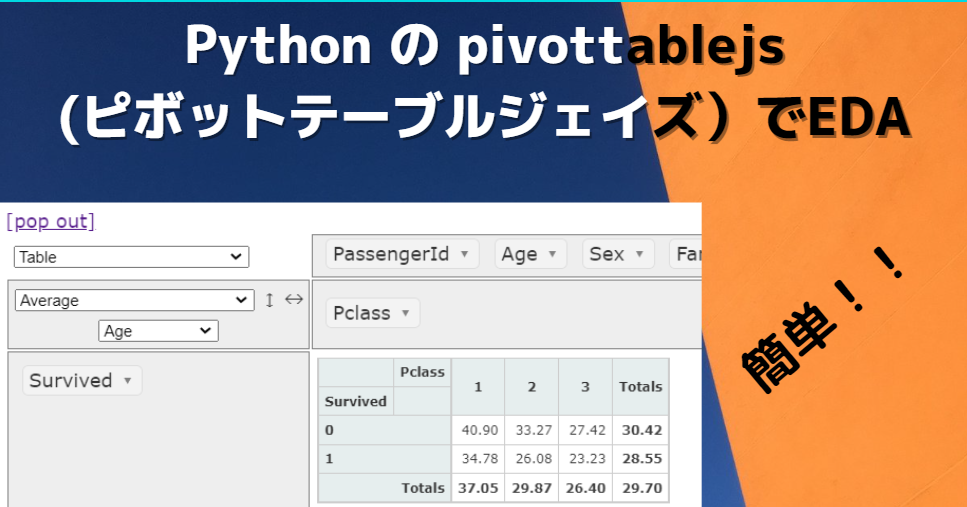
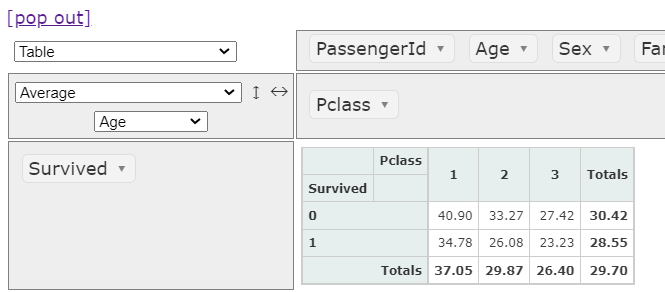
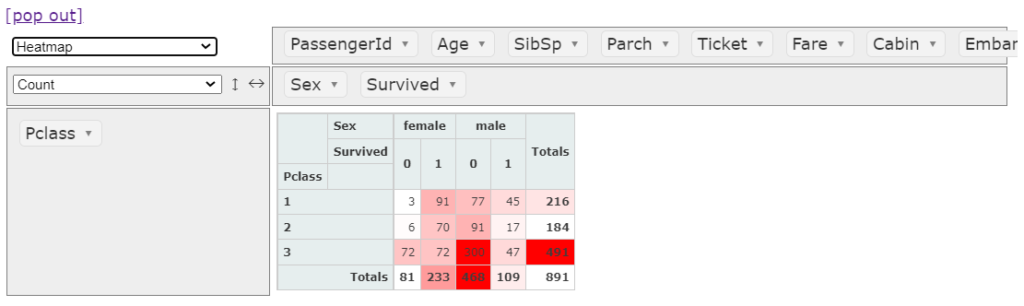
pivottablejs(ピボットテーブルジェイズ)を起動すると次のような画面になります。すでに下表ではPclassごとの男女別生存者の数をみることができますね。
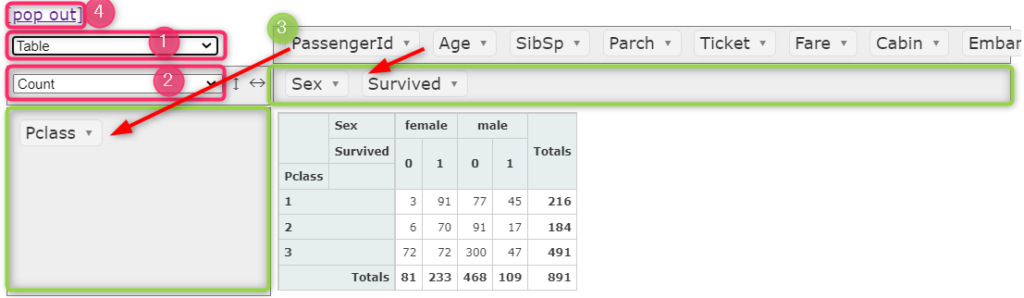
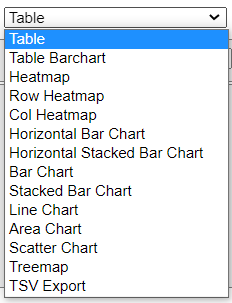
① 可視化方法を選択します。
様々な可視化方法を選択することが出来ます。後ほど主なものを実践してみましょう。
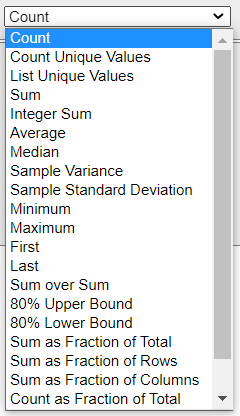
② データのタイプを選択します。
様々なタイプを選択することが出来ます。用途に合わせて選択してください。
③ それぞれ、可視化したいデータ項目を割り当てます。
それぞれのデータ項目をドラッグ&ペーストで割り当てることができます。
その為、直感的に操作ができ、すぐに可視化が可能です。
ここの例では、Pclassにおける男女別、生存者と死亡者の人数を確認しています。
④ pop out でブラウザ上で操作が可能

pop out をクリックすると、htmlファイルが作成され操作しているフォルダ内に保存されます。保存されたhtmlファイルを開くとピボット操作がブラウザ上で実行が可能になります。jupyter notebookなどで実行していると狭く感じますが、ブラウザ上で実行すると広く見やすくなりますので便利ですね。ただし、ブラウザ上で実施しなくても特に問題ありません。
pivottablejsとpandasのgroupbyやpivot_tableとの操作比較
生存者と死亡者の平均年齢をみる。
groupbyでみた場合
df.groupby("Survived").mean()["Age"]結果は以下の通り
Survived
0 30.415100
1 28.549778
Name: Age, dtype: float64pivottablejsでみた場合
クリック操作で Survived と Age を選択するだけ。
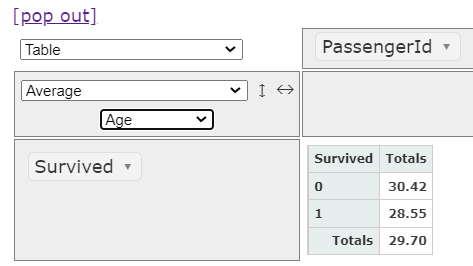
Pclass 毎の 生存者と死亡者の平均年齢を確認する
pivot_tableでみた場合
以下のようなコードを入力します。
pd.pivot_table(df, index="Survived", columns = "Pclass", values = "Age")結果は次の通り。慣れてしまえばこれはこれでよく使います。
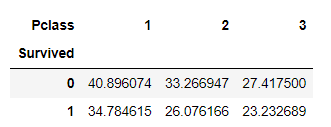
pivottablejsでみた場合
クリック操作で Survived と Pclass と Age 選択するだけ。いろいろと考えながらデータを動かしていく場面ではpivottablejsは楽ですね。
直感的に扱えるから、本来のデータとより集中して向き合えることができますね。
pivottablejs で あらゆるデータの可視化方法
pop out 下の可視化の選択から、基本的な可視化手法が選択すると、自動的に描画してくれます。ひとつひとつコードを書いてグラフを作るわずらわしさから解放できますね。Python上級者の方からは怒られそうですが、楽です。基本的なEDAであれば、十分戦力になってくれると思います。
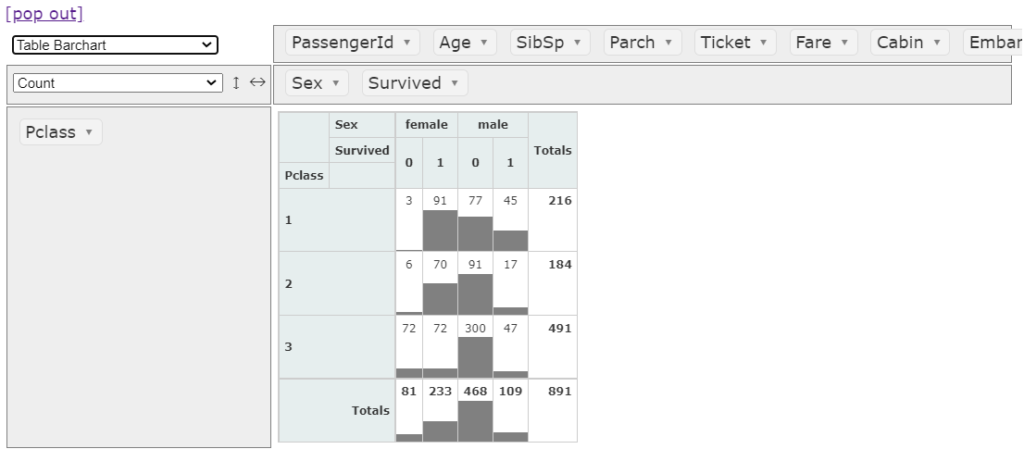
バーチャート エクセルでいう データバー
Pclassごとの男女の生存者を数値だけでなく表の中にバーとしてあらわしてくれますので、直感的にデータを捉えることができます。
ヒートマップ エクセルでいう カラースケール
こちらもバーチャート同様、数値を色で表現してくれますので直感的にデータを認識できます。
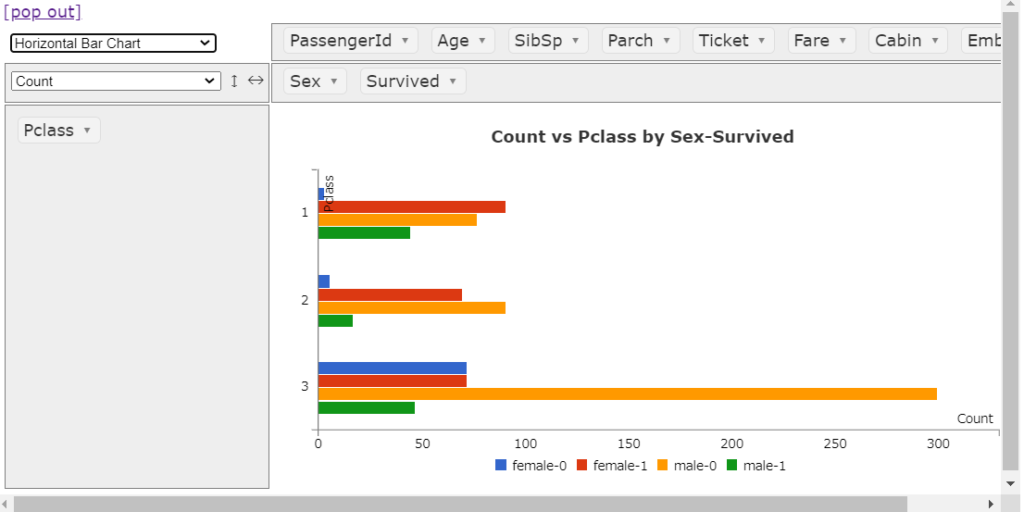
横棒グラフ
一般的な水平バーチャートもきれいに描画してくれます。
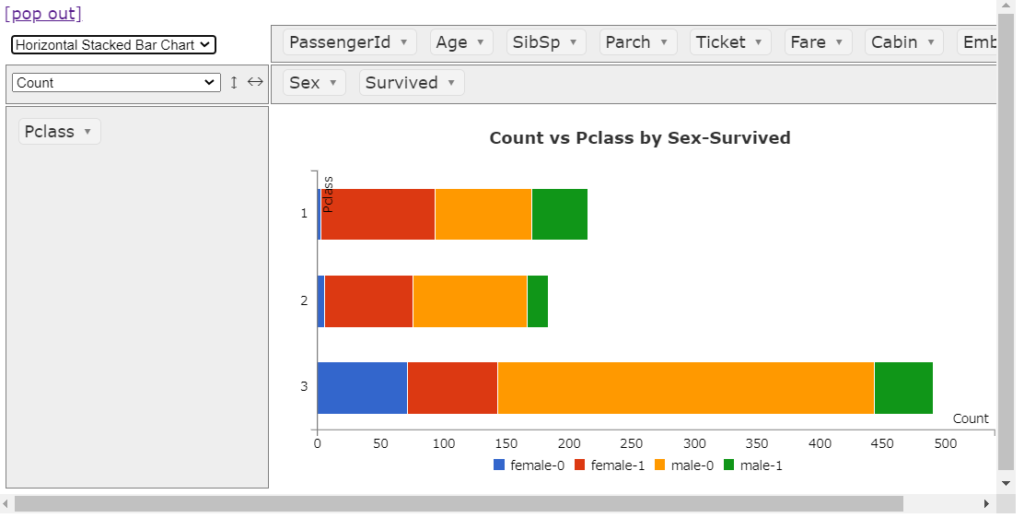
横積み上げ棒グラフ
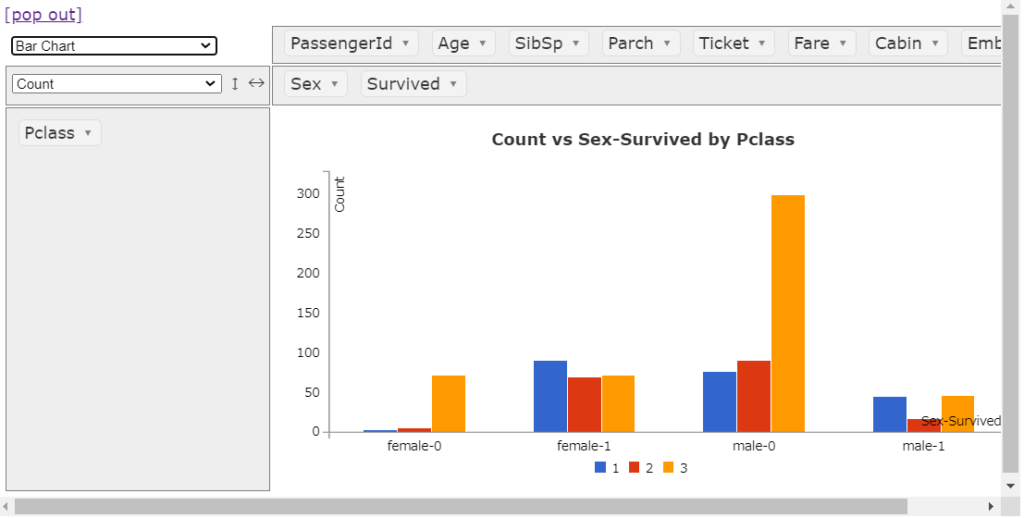
棒グラフ
このまま、レポートへの貼り付けもできそうです。
積み上げ棒グラフ
基本的な棒グラフ(積み上げ、水平)は余裕ですね。
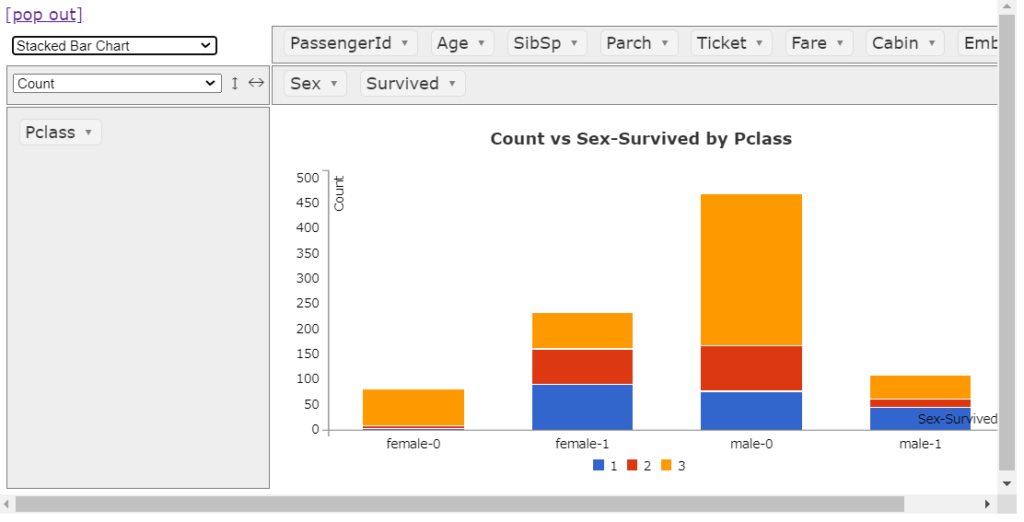
折れ線グラフ
つづいて、折れ線グラフです。こちらもきれいなグラフがかけています。
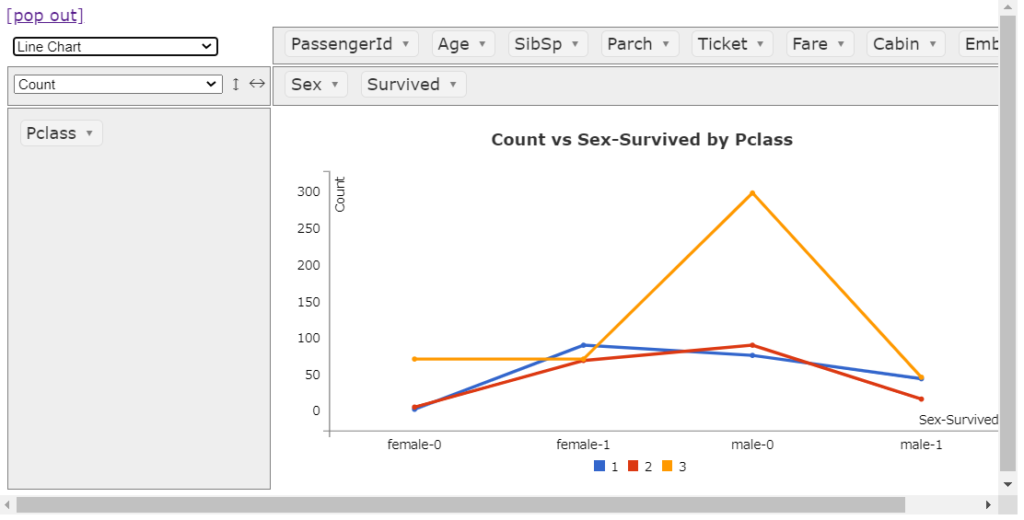
面グラフ
個人的にはあまり使いませんが、目的によって使い分けてみてはいかがでしょうか。うーん美しい。
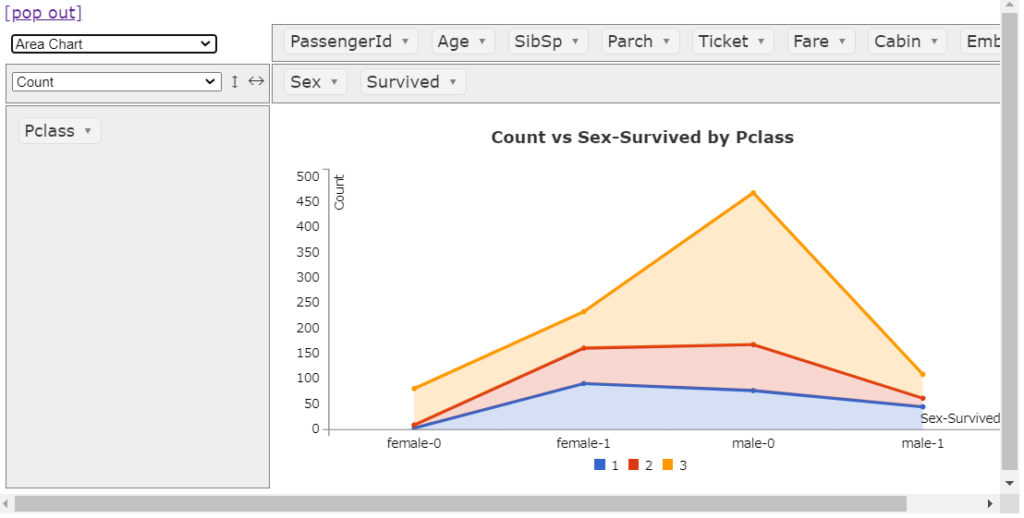
ツリーマップ
こちらも面白いですね。色と面積で直感的にデータを把握できます。
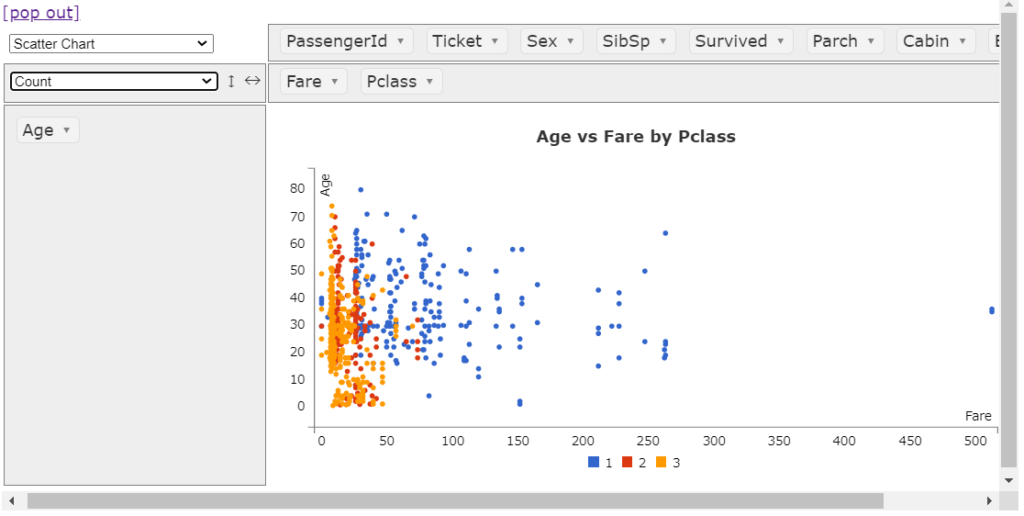
散布図
散布図です。こちらはよく使います。とくにx軸、y軸を頻繁に入れ替えてあーでもない、こーでもないと議論を重ねるのにドラッグ&ドロップで操作ができるは便利ですよね。
まとめ
最後まで読んでいただきありがとうございました。今回は、エクセルのようなピボットテーブル&グラフ操作をPythonでも実装できる、pivottablejs を紹介いたしました。データ分析は、課題解決が主目的ですので特にデータをよく見て推察、仮説を立てる能力が非常に重要です。そんな中で、データを簡単に可視化してくれるこのpivottalbeljsは、推察、仮説を考えることに集中させてくれる頼もしいアイテムだと思います。積極的に使用して効率的、効果的にビジネスに価値を与えましょう。
またねー、みんなも使ってみてねー
ばいばーい
今日から使っちゃお♪
探索的データ分析に役に立つライブラリとして、プロファイルというものがあります。別のブログ記事にまとめてありますので、ご興味がございましたらこちらもあわせてご覧ください。


コメント